¿Cómo redactar información sensible de archivos de audio?
July 18, 2022 | 5 minutes read
A medida que las llamadas al 911 y otras formas de grabación de audio se comparten con más frecuencia debido al aumento de las plataformas de redes sociales, es imperativo que los consumidores tengan la tecnología necesaria para proteger no sólo su privacidad personal, sino también la privacidad de los demás. Aunque la redacción de archivos de audio ha sido tradicionalmente una tarea costosa y que conlleva mucho tiempo, ahora existen programas de redacción automática de audio que completan esta misma tarea en cuestión de segundos.
Hoy veremos dos métodos para redactar archivos de audio o audio en archivos de video:
- Manualmente, introduciendo las horas de inicio y fin de la información sensible.
- Automáticamente, utilizando la tecnología de reconocimiento del habla para localizar dónde se divulgó información sensible, sin ningún esfuerzo por parte del usuario.
1- Encubrir o silenciar manualmente la información sensible del audio
Cuando se busca redactar el audio manualmente utilizando un software de redacción de audio, los usuarios pueden realizar la tarea de diferentes maneras siguiendo los siguientes pasos:
- Seleccione las horas de inicio y fin en las que se divulga la información sensible. Puede hacerlo siguiendo uno de los métodos siguientes:
- Introduzca manualmente los valores de inicio y fin de donde quiere empezar y terminar la redacción del audio.
- Escuche el archivo de audio y, a continuación, pulse el ícono de la mano junto al botón Start (Inicio) cuando empiece a oír la información sensible para recoger la hora de inicio y luego pulse el ícono de la mano junto al botón End (Fin) cuando ya no se escuche información sensible para recoger la hora de fin de su redacción de audio.
- Escuche el archivo de audio y, a continuación, pulse el botón Press & Hold (Mantener Pulsado) cuando empiece a oír la información sensible para recoger la hora de inicio y siga pulsando el botón hasta que deje de oír la información sensible, entonces suéltelo para recoger la hora de finalización. (Figura 1: abajo)
- Resalte las partes de la onda de audio en las que se está revelando la información sensible y esto actualizará automáticamente las horas de inicio y fin. (Figura 2: abajo)
- Seleccione los botones Mute (Silenciar) o Bleep (Encubrir) para aplicar a las horas de inicio y fin seleccionadas en el primer paso.
- Haga clic en el botón Mute Selected Time (Silenciar la Hora Seleccionada).

Figura 1: Mantenga pulsado y haga clic en el botón Mute Selected Time (Silenciar el Tiempo Seleccionado).

Figura 2: Resalte la onda de audio y haga clic en el botón Mute Selected Time (Silenciar el Tiempo Seleccionado).
2- Automáticamente, mediante el uso de tecnología de reconocimiento del habla
Además de redactar manualmente las grabaciones de audio los usuarios pueden realizar este proceso automáticamente mediante la transcripción automática. Esto se debe a que el software de redacción automática de audio cuenta con la funcionalidad de transcripción automática. De este modo, los usuarios no sólo ahorran un tiempo precioso, sino también recursos, especialmente si hablamos de miles de archivos de audio que necesitan ser redactados.
Para iniciar la redacción automática de audio de su archivo, primero tiene que importar su archivo al sistema y luego seguir los siguientes pasos:
- En el panel de transcripción haga clic en el botón Auto Transcribe (Transcripción Automática). (Figura 3: abajo).
- Seleccione Spoken Language (Idioma Hablado) y Number of Speakers (Número de Hablantes) en el archivo de video o audio y luego haga clic en Transcribe (Transcribir). (Figura 4: abajo).
- Cuando el sistema haya terminado la transcripción, todo el discurso se convertirá en texto y se mostrará en el panel de transcripción. (Figura 5: abajo).
- Ahora que tiene la transcripción lista puede redactar el audio con uno de los siguientes métodos:
- Resaltar y Redactar. (Figura 6: abajo)
- Simplemente resalte el texto que desea redactar.
- Haga clic con el botón derecho del ratón sobre el texto resaltado.
- Seleccione Mute (Silenciar) o Bleep (Encubrir) para redactar el texto resaltado.
- Buscar y Redactar. (Figura 7: abajo)
- Desde el panel de transcripción puede buscar cualquier palabra.
- El sistema resaltará automáticamente todas las palabras que coincidan.
- Haga clic en los íconos Mute (Silenciar) o Bleep (Encubrir) en la parte superior del panel para redactar todas las palabras que coincidan.
- Redactar utilizando el panel de análisis. (Figura 8: abajo)
- La transcripción automática cuenta con un panel de análisis. El panel de análisis analiza automáticamente el discurso y organiza toda la información sensible en diferentes categorías.
- Filtre por categorías como nombres, números de teléfono, direcciones y más de otras 20.
- Haga clic en Mute (Silenciar) o Bleep (Encubrir) para redactar una o más categorías.
- Y ya ha terminado ?.

Figura 3: Transcriba automáticamente desde el panel de transcripción.

Figura 4: Seleccione el Spoken Language (Idioma Hablado) y el Number of Speakers (Número de Hablantes).

Figura 5: Convierta de habla a texto.
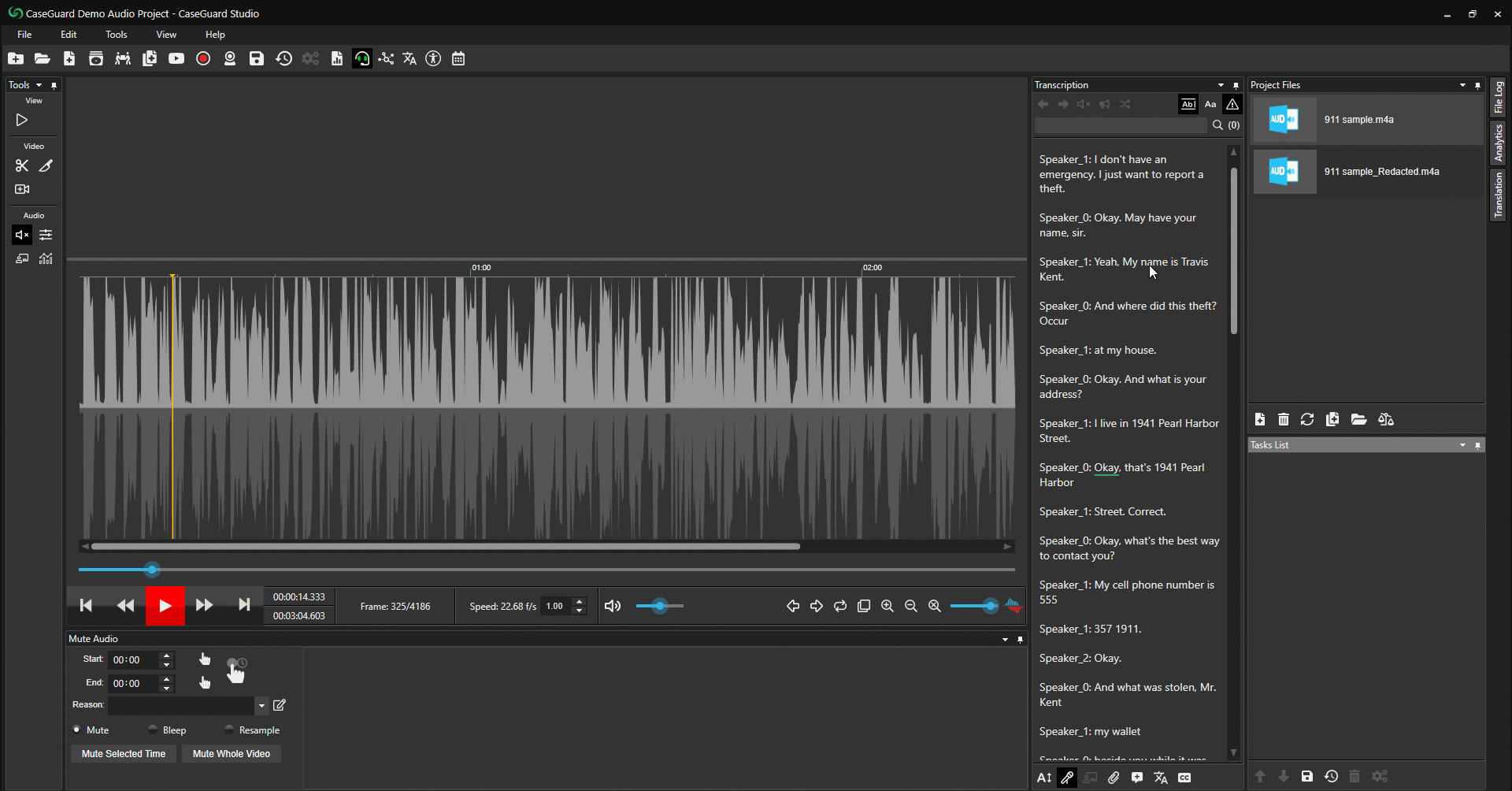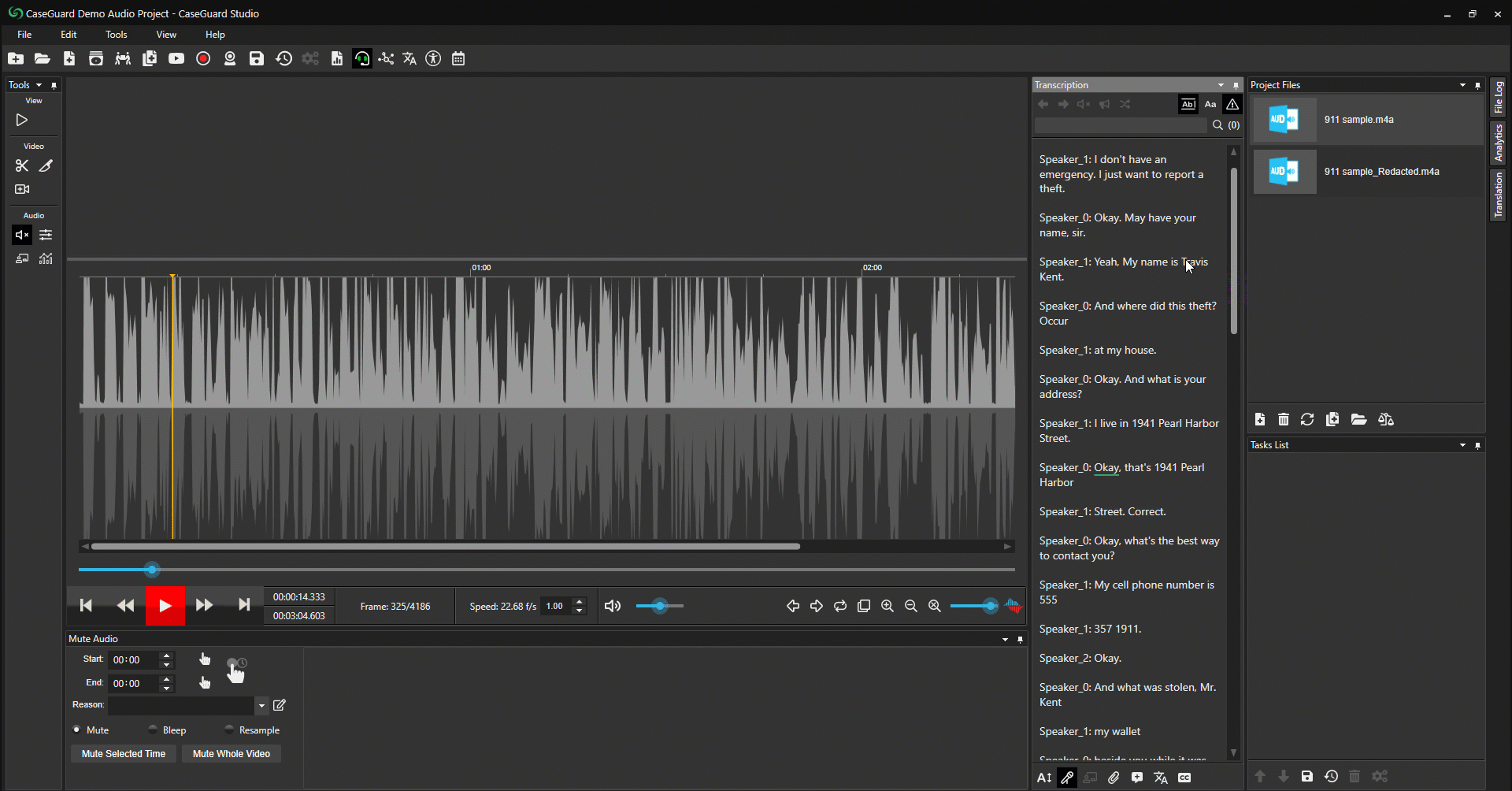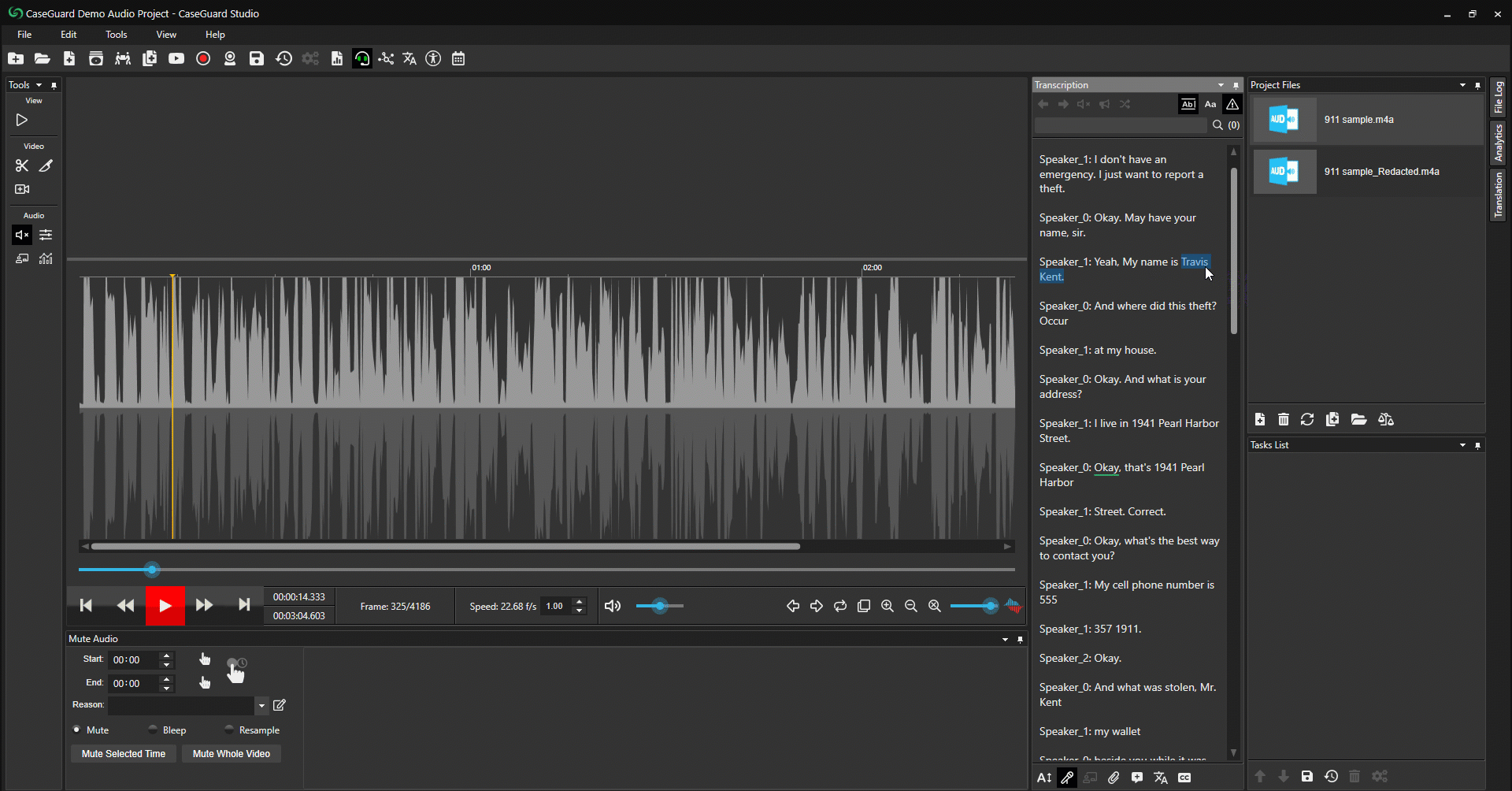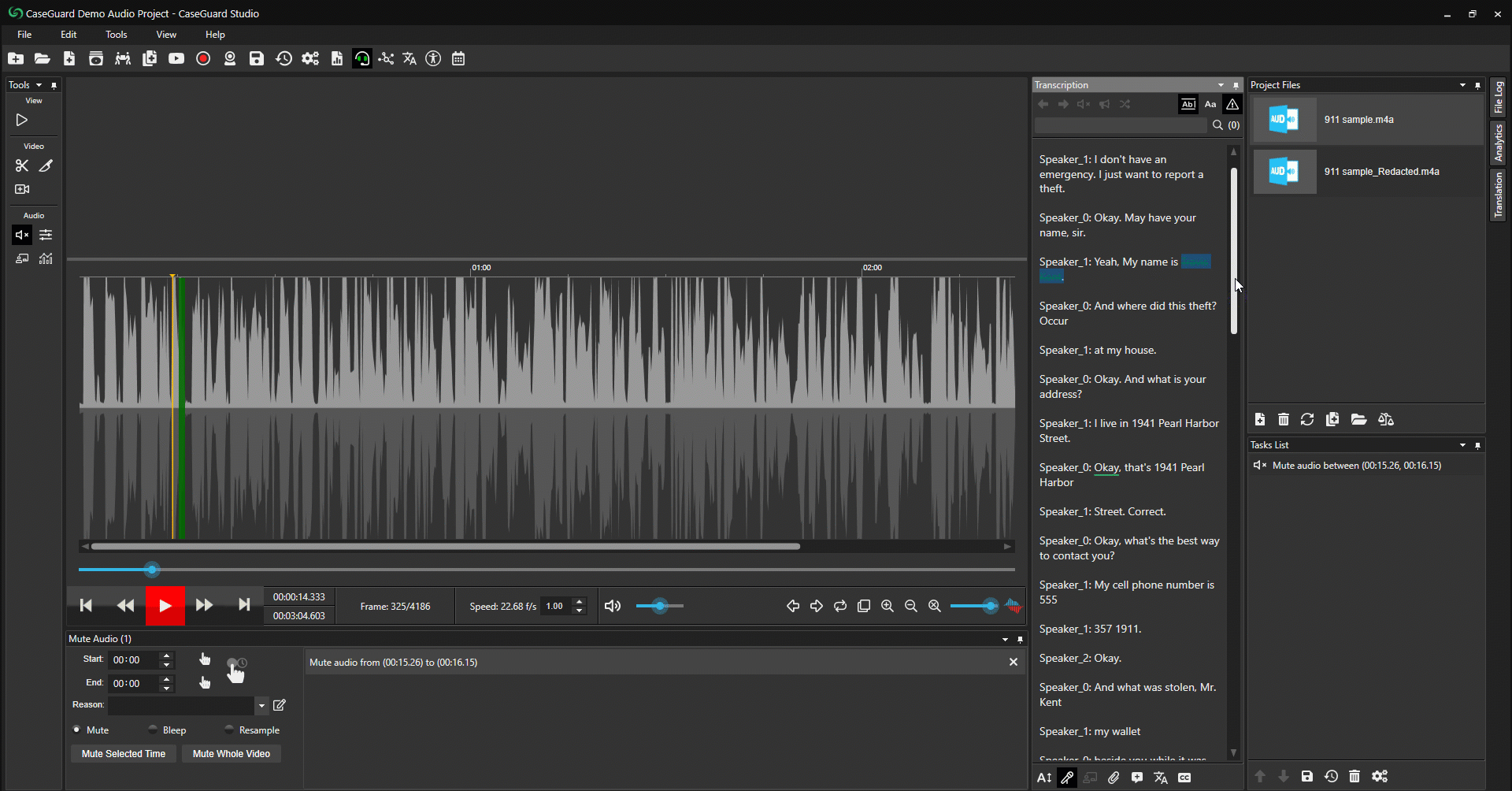
Figura 6: Resalte el texto que desee redactar, haga clic con el botón derecho del ratón para silenciar o encubrir.

Figura 7: Busque las palabras que desee redactar, encuentre todas, haga clic en silenciar o encubrir.

Figura 8: Redacte utilizando el panel de análisis, filtre por categoría, luego silencie o encubra.
Ejemplo de redacción automática de audio
Vea el siguiente ejemplo para comprobar la rapidez con la que se puede redactar información sensible de un audio utilizando tecnologías de transcripción y reconocimiento del habla.